
Workflow orchestrators: Metaflow, Kedro, Luigi, Airflow, Flyte, Prefect and others
There are probably more workflow orchestrators available than there are people at your company.

Why reinvent the wheel? Because it’s fun.

It’s a lot easier to say “I can make that tool better” rather than say, “how do I create new value for my client?”
Now, if your client is thousands of time-constrained data scientists who hate all of these things but want them to work exactly how they hope they do, then sure - try to make that tool better.
Just to get you warmed up

Star History Matters
Why? 1) it’s a signal of how much documentation and SO help there is, 2) it’s a signal of how stable it is, 3) it’s a signal of your nerdiness. I’m sure you’ll like these plots as much as I do, you savvy DS.
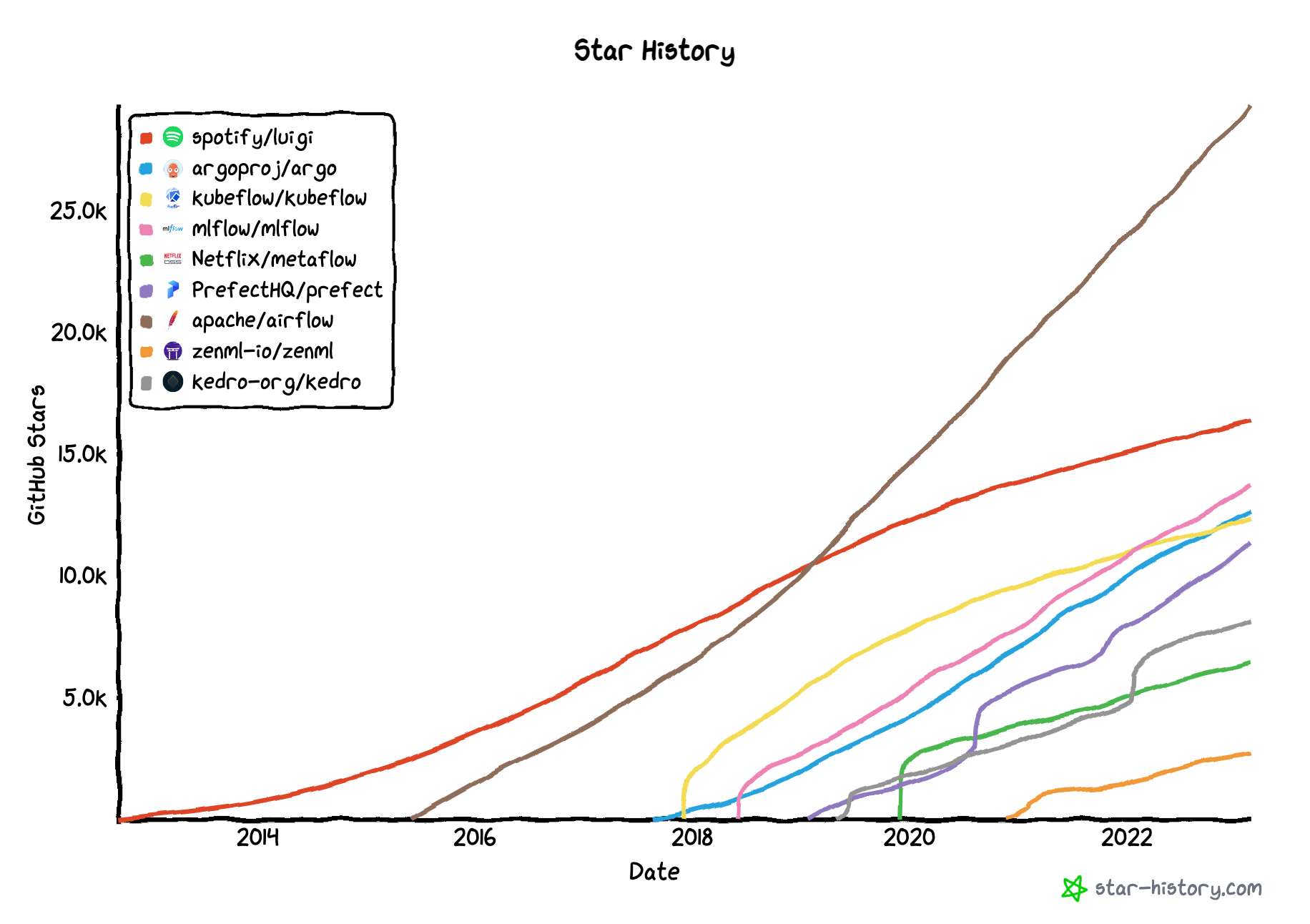
Luigi vs. Argo, Kubeflow, metaflow, mlflow, prefect, airflow, zenml, kedro
I love star-history.com (for plot below), idea stolen from this blog.

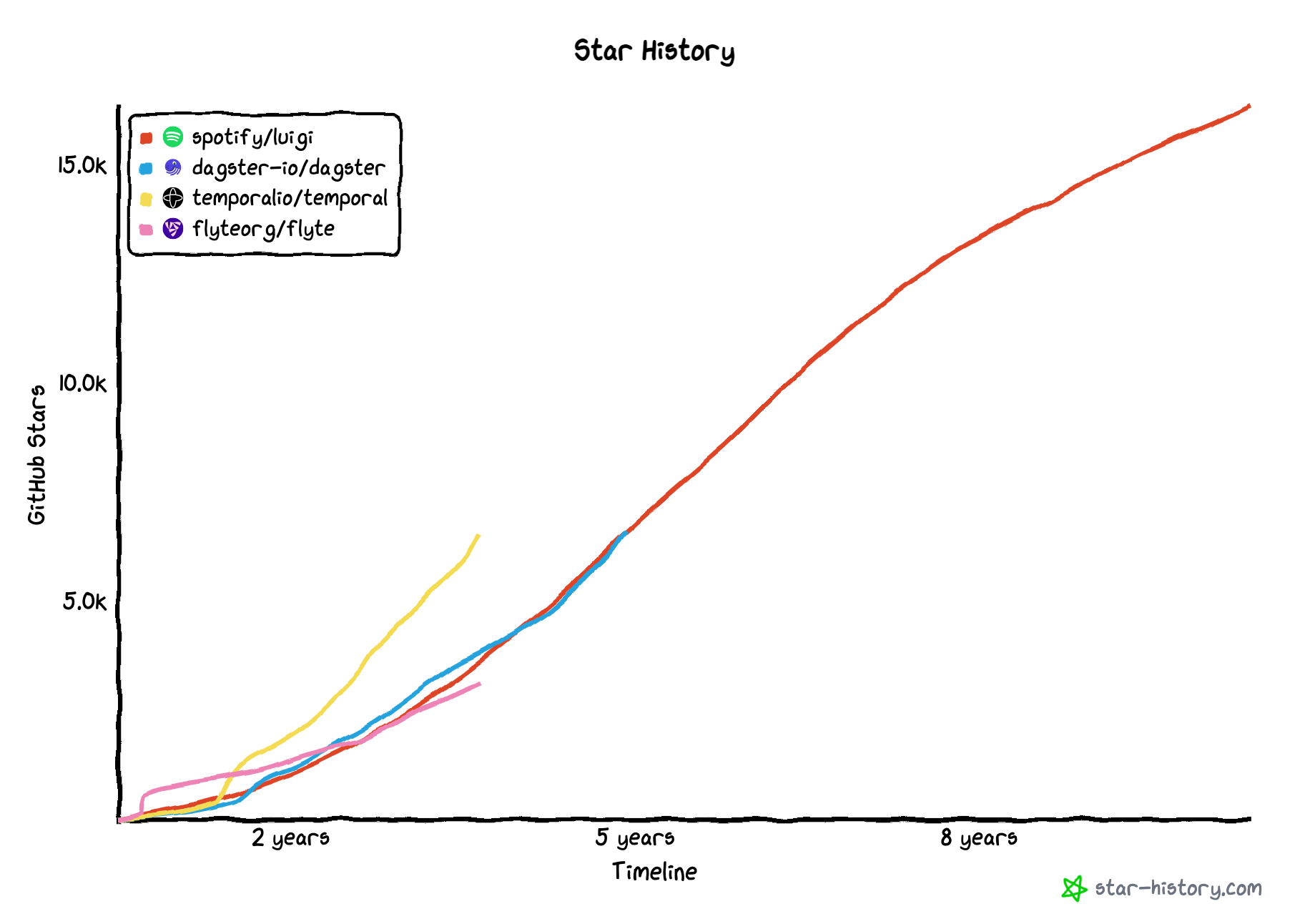
Luigi vs. Dagster, temporal, flyte

Star Ratings aren’t everything
A few things:
There’s faster adoption today beause there are more data engineers than there were before.
Just because something’s popular, doesn’t mean it’s more valuable. Take this R popularity plot below per SO.

This plot above is misleading, because R is mostly for data science (like pandas):

Add pandas in and you see it’s 50-50 what questions people are asking for.
Your tool depends on your use case
Most of the tools above are build for Data Engineers - folks who care about deploying pipelines in production on some server or something. Kedro and Metaflow are the only two I’ve seen specifically marketed for data scientists, while others are a mix of DS/ML Eng/Data Eng.
I can’t compare all these for you. I’m just writing this blog post for my own use cases. Here’s my workflow as a DS:
I want to be able to run it locally as easily as I run it remotely. Most of my prototyping is on my mac, but then I want to scale my compute remotely.
Debugging: I want to be able to inspect outputs locally
I want to be able to re-run tasks easily (say, if task 5 dies) without running all prior steps. Step 1 might be load/clean data. Step 2 might be build ML model. Step 3 might be make plots.
Parallelization/dynamic inputs. I want to scale
I don’t care about retrying tasks (if my tasks fail, it’s because my data are bad and I want them to fail). I feel like retrying is for when you rely on internet connections and hit timeouts or something.
Flyte vs. Metaflow
Design:
Flyte: Decorators: I like prefect because it’s all decorators. Metaflow has a strange interface with the class objects. But Flyte is also all decorators.
Metaflow: Classes: Metaflow is designed with a single class with methods that chain and all the data are stored in that class, which is persisted to disk.
Running locally/remotely:
Both: Run locally/remotely. Can scale on kubernetes (k8s).
Flyte: Runs out of the box (no k8s required) (just run the python script). You can launch and run it on a local cluster.
Metaflow: scales to k8s or AWS batch
Interact/debug the output: (need to cache)
Flyte: Need to cache each task
Locally:
Remotely, it saves all the output in Pickle files. Like after running a workflow, this node had 3 sklearn model objects in it. Just supply the execution id. Remember you can run a task “remotely” on a local cluster.
Metaflow:
Re-run specific tasks: Flyte lets you re-run specific tasks, though I haven’t tried this and it seems pretty complicated. I’m sure I could build a CLI that makes this more efficient, but Metaflow has a pretty clean interface for resuming a task.
Interacting with output
from flytekit.remote import FlyteRemote
from flytekit.configuration import Config
remote = FlyteRemote(
config=Config.auto(),
default_project="flytesnacks",
default_domain="development",
)
# Specify the run_id
execution_id = "fac7321e7902348da9c3"
execution = remote.fetch_execution(name=execution_id)
remote.sync(execution, sync_nodes=True)
# get execution output keys
len(execution.outputs["o0"])
# 3When running it locally:
coder@union-sandbox-00u8jkhhfd2pivdrp5d7-55685d656c-tmt7s:~/flyte$ pyflyte run \
flyte_demo/workflows/parallelism.py training_workflow \
--hp_grid '[{"C": 0.1, "max_iter":1000}, {"C": 0.01, "max_iter":1000}, {"C": 0.001, "max_iter":1000}]'
TrainArgs(hyperparameters={'C': 0.1, 'max_iter': 1000.0}, data=StructuredDataset(uri=None, file_format='parquet'))
TrainArgs(hyperparameters={'max_iter': 1000.0, 'C': 0.01}, data=StructuredDataset(uri=None, file_format='parquet'))
TrainArgs(hyperparameters={'max_iter': 1000.0, 'C': 0.001}, data=StructuredDataset(uri=None, file_format='parquet'))
[LogisticRegression(C=0.1, max_iter=1000.0), LogisticRegression(C=0.01, max_iter=1000.0), LogisticRegression(C=0.001, max_iter=1000.0)]When runing remotely, it provides an execution id: (added the —remote flag)
coder@union-sandbox-00u8jkhhfd2pivdrp5d7-55685d656c-tmt7s:~/flyte$ pyflyte run \
--remote \
flyte_demo/workflows/parallelism.py training_workflow \
--hp_grid '[{"C": 0.1, "max_iter":1000}, {"C": 0.01, "max_iter":1000}, {"C": 0.001, "max_iter":1000}]'
Go to https://sandbox.union.ai/console/projects/flytesnacks/domains/development/executions/f535a4fe73efd4a248fc to see execution in the console.Dashboard:


Comparisons
Website: https://mymlops.com/tools
Kedro vs ZenML vs Metaflow: Which Pipeline Orchestration Tool Should You Choose? (Feb 2023)
MLOps: Task and Workflow Orchestration Tools on Kubernetes → Kubeflow | MLflow | Metaflow | Flyte | ZenML | Airflow | Argo | Tekton | Prefect | Luigi (May 2021 Medium)
Data Science Workflow Automation Tools: Flyte, Kedro, Metaflow, and Pachyderm (Jan 2023)
Why not join the approaches?
Doesn’t have to be a one-size fits all.